 TECHaas
TECHaas
Flutter で画像認識 - その2
「Flutterでカメラにアクセスして、AI (Machine Learning) で画像認識などしてみようと思います」の続きです.
モバイルデバイス用の MLKit を使って、カメラで撮った画像のテキストの解析をしてみます.
MLKitは、Google が提供している Machine Learning 用のAPIです。
機械学習の実装面をみると、モデルを生成する学習フェーズと、できあがったモデルを使う推論の2フェーズに分けられます。 MLKit では、学習済みの推論モデルが提供されていて、それをモバイルデバイス等で使える様にしたものです。
用途にあう推論モデルがあれば、比較的簡単に AI 機能をアプリに組み込むことができます。
提供されているモデルには、制限などがありますのであらかじめ調査が必要かと思います。 特に、Android と iOS で提供されているモデルや機能が違ったりするので、気をつけてください。 (せっかくアプリを flutter で組んでも、MLKitが対応してないとかじゃ笑えないので)
機能やサポートされているプラットフォームなどについては、以下が参考になります。 また、MLKit は開発が継続中のプロダクトなので、バージョンアップの速度なども早いです。
今回は、 Text Recognition を使って、画像中のテキスト認識をしてみます。
ソースコードは以下に置いてあります。
まず、MLKit のパッケージを組み込みます。
pubspec.yaml に以下を追加します。
dependencies:
...
google_ml_kit: ^0.7.0
それから、今回はText Recognitionを使うので、モデルは実行時にダウンロードすることになります。
そのための設定として、 Android では、app/src/main/AndroidManifest.xml に以下を追加します。
<manifest >
<activity >
...
<meta-data
android:name="com.google.mlkit.vision.DEPENDENCIES"
android:value="ocr" />
機能によって、モデルのダウンロードが必要ないものと必要なものがあります。
また、valueの値は、使う機能によって変更します。 (複数の場合には、,(カンマ)で追加指定します)
では、実際に認識を実行されるところを、少し細かく確認していきます。
class _DetectViewState extends State<DetectView> {
late final String _imagePath;
late final TextDetector _textDetector;
Size? _imageSize;
List<TextElement> _elements = [];
_imagePathが、CameraViewから渡された画像のパス名になります。
TextDetectorが、文字認識用のMLです。MLKit で提供されているものは、英数字だけしか認識しません。
_imageSizeには、画像の大きさが入ります。後で、描画用に使います。
認識されたテキストには、そのテキストの境界も返されますが、座標系は元画像のままになります。
そこで、画像の大きさから実際にスマホの画面に表示する時の倍率を計算してあげます。
_elementsには、認識された結果が入ります。
推論モデルによって、返ってくるものが異なりますので、API Documentなどを参照してください。
_getImageSize()は、写真画像の大きさを取得します。
Future<void> _getImageSize(File imageFile) async {
final Completer<Size> completer = Completer<Size>();
final Image image = Image.file(imageFile);
image.image.resolve(const ImageConfiguration()).addListener(
ImageStreamListener((ImageInfo info, bool _) {
completer.complete(Size(
info.image.width.toDouble(),
info.image.height.toDouble(),
));
}),
);
final Size imageSize = await completer.future;
debugPrint("size: ${imageSize}");
setState(() {
_imageSize = imageSize;
});
}
Imageは、読み込みに少し時間がかかるので、サイズを求めるのがちょっと面倒です。
最終的なサイズは、_imageSizeにsetState()されてサイズが確定した時点で再描画されます。
実際にテキスト認識を行っているのは、_recognizeText()になります。
ここがキモで、他の部分は、まぁ補助です。
void _recognizeText() async {
_getImageSize(File(_imagePath));
final inputImage = InputImage.fromFilePath(_imagePath);
final RecognisedText recognisedText = await _textDetector.processImage(inputImage);
// Finding and storing the text String(s) and the TextElement(s)
for (TextBlock block in recognisedText.blocks) {
print('block: ${block.text}');
for (TextLine line in block.lines) {
print('text: ${line.text}');
for (TextElement element in line.elements) {
_elements.add(element);
}
// }
}
}
setState(() {});
}
_textDetector.processImage() が推論モデルで実際のテキスト認識をしている部分です。
時間がかかるので、非同期実行されて、RecognisedTextとして結果が返ってきます。
RecognisedTextの中のblocksが、テキストが含まれている領域全体で、その中にlinesとして行が、また、行にはelementsとして要素が含まれます。
この辺は単語として区切ることができる欧文用のモデルなので、それを意識した結果出力になっているんだと思います。
今回は、認識されたelementsを、_elementsに積んでいきます。
Stateが初期化されたら、与えられたイメージの認識をすぐに開始します。
@override
void initState() {
_imagePath = widget.imagePath;
_textDetector = GoogleMlKit.vision.textDetector();
_recognizeText();
super.initState();
}
@override
void dispose() {
_textDetector.close();
super.dispose();
}
UIの方は、与えられたイメージを描画して、その上に認識されたテキストの情報を描画しています。
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: const Text('Picture')),
body: _imageSize != null
? Container(
color: Colors.black,
child: Center(
child: CustomPaint(
foregroundPainter: TextDetectorPainter(
_imageSize!,
_elements,
),
child: AspectRatio(
aspectRatio: _imageSize!.aspectRatio,
child: Image.file(
File(_imagePath),
),
),
),
))
: Container(
color: Colors.black,
child: Center(
child: CircularProgressIndicator(),
),
),
);
}
Flutter の2D描画は、CustomPaintを使います。
CustomPaintに、foregroundPainter:を指定すると、child:をCanvasとしてその上に、2D描画ができるようになります。
(ちなみに、下に描画するには、painter:で指定します)
AspectRatioは、特定の縦横比を保ったまま、child:を拡大縮小して最大になる様にリサイズします。
あと、_imageSizeが計算されるまでは、CircularProgressIndicatorを表示して、計算できたらサイズからaspectRatioを求められるので、イメージを描画します。
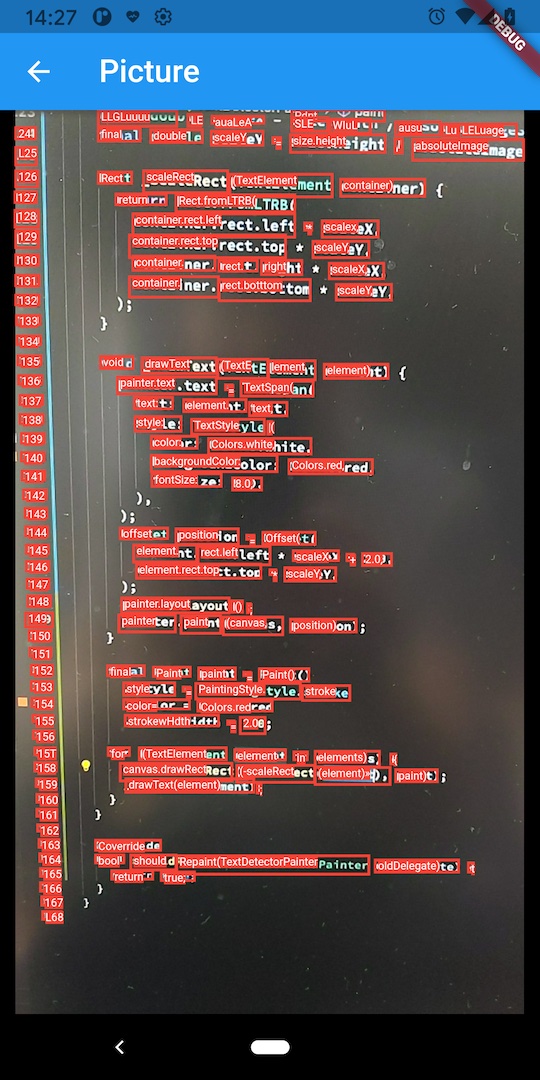
残りは、TextDetectorPainter ですが、これの説明は割愛します。
認識されたテキストの領域element.rectを描画して、中身のelement.textを描画している感じです。
簡単ですが、デバイスで写真を撮って、その中のテキストを認識させてみるとこんな感じになるでした。 実際に実行してみた結果をみると、ソースコードの様にきちんとしたキャラクタの認識はかなり高精度かなという感じです。 (画面をカメラで撮っています)
また、電卓を撮ってみたときはこんな感じです。一部認識していないところがありますね。また、認識する時の範囲も違います。

このあと、どうやったら認識精度を上げられるか等を試す予定です。 やってみるとわかるのですが、画像が傾いたりしていると途端に精度が下がります。 その辺、精度を上げるための前処理などを噛ませてあげたほうが良いかと思います。 (手を動かすことの大切さっていうのは、こういうところです。ITでも肌感覚っていうのは大事で、その積み重ねがプロジェクトのリスク管理となります)
また、MLKitでは、Tensorflow Lite 用に学習されたモデルを読み込んだりできます。 TF使えば、特定用途に向けた強化学習とかも可能だと思いますので、そちらを試していきます。 目処が立ったら、また続きを書こうと思います。